- Revenera Community
- :
- Code Insight
- :
- Code Insight Knowledge Base
- :
- FlexNet Code Insight - Scan Profile Options Explained
- Mark as New
- Mark as Read
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
FlexNet Code Insight - Scan Profile Options Explained
FlexNet Code Insight - Scan Profile Options Explained
FlexNet Code Insight provides scan profiles as a way to abstract and re-use scan settings across multiple projects.
Scan profiles continue to be expanded as new versions of FlexNet Code Insight are released.
In the 2020 R1 release, we introduced a new setting that allows control over the minimum number of source code fingerprint matches that must be present in a scanned source code file before that file is reported as having source matches.
As you can imagine, this capability has raised several questions internally, so I wanted to explain all of the available scan profile settings beyond what is documented in the Installation and Configuration Guide.
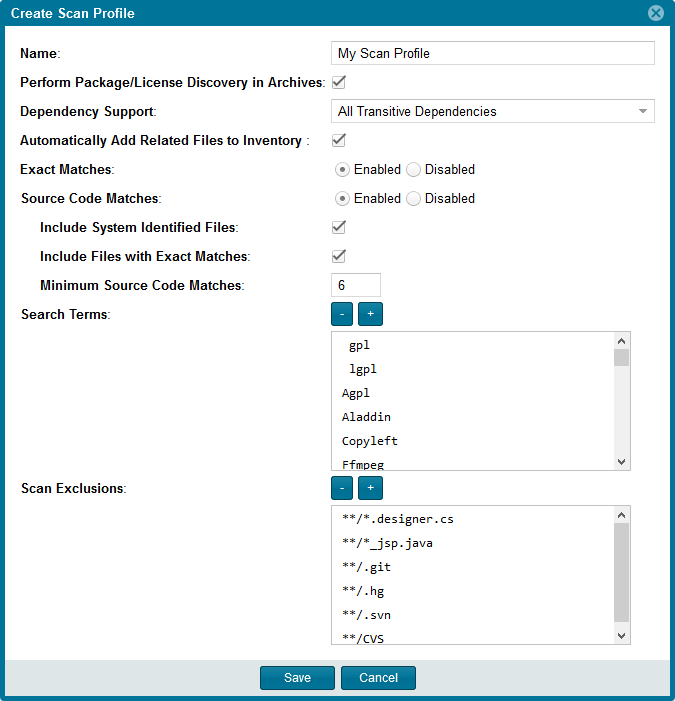
Attached is a screenshot of the scan profile dialog.
To create a new scan profile, you must be a user with the administrator role. You can create a new scan profile by navigating to Administration > Scan Profiles.
The scan profile controls scan settings in the following categories:
- Scanning in archives
- Dependency support
- Automatically adding related files to inventory items
- Exact match options
- Source code match options
- Search terms
- Scan exclusions
Scanning in Archives
FlexNet Code Insight's automated discovery module is able to scan within archive files to automatically identify components and evidence of file-level licenses. This option is useful where you do not want to perform forensic-level scan and manual analysis on files within archives, but do want to ensure that components and licenses within archives are reported.
An alternative to using this option is to burst all archives prior to scanning (refer to Uploading a Project Codebase section in the User Guide for more details).
Dependency Support
FlexNet Code Insight allows control over the level (depth) of dependency information returned by a scan. There are three options available:
- No Dependencies: only top-level inventory items will be created
- Only First Level Dependencies: top-level inventory items and their direct dependencies will be created and named accordingly
- All Transitive Dependencies: top-level inventory items, their direct dependencies, and all remaining transitive dependencies will be created and names accordingly
- This option has the likelihood of creating false-positives by over-reporting on transitive dependencies due to processing all build targets in package-manager manifest files. If accuracy is critical to your team, you may be better served with integrating into your CI/CD build infrastructure using one of Code Insight's remote scan agents: Azure DevOps, Bamboo, GitLab, Jenkins, or TeamCity. The remote scan relies on the resolved build artifacts for a more accurate bill of materials.
- The Code Insight remote scan plugins can be downloaded from the Flexera Community - Product Downloads.
- Note that transitive dependencies will be names as dependencies of the top-level inventory item, not the immediate parent. A future release of FlexNet Code Insight will provide a tree view of inventory items to address this limitation.
- For a detailed description of Code Insight dependency support, see the Automated Analysis chapter in the User Guide.
Automatically Adding Related Files to Inventory Items
FlexNet Code Insight support automatic addition of scanned codebase files to existing inventory items based on data available in automatic detection rules. Select this option to maximize the number of scanned files that are automatically associated with inventory items.
Exact Match Options
Exact matching relies on MD5 file hash data in the Compliance Library. An exact match indicates that a scanned codebase file is a bit-for-bit match to a file seen in one or more open source projects. This is a very strong indicator that your team did not product this file and that is came from the open source community.
Source Code Match Options
Source code matching relies on source code snippet data in the Compliance Library. A source code fingerprint match indicates a fragment of code from a scanned source code file that has been seen in one or more files across one or more open source projects. The significance of the match typically depends on three factors:
- Coverage: the percentage of the matching remote third-party file contained in the scanned source code file
- Clustering: the density/proximity of matches in the scanned source code file
- Uniqueness: an indication of how often the matches in the scanned file are seen in the Compliance Library
We combine these three elements into a composite index called Code Rank.
Since source code fingerprint matches require manual analysis and expand scan times, we have added several inputs that reduce the number of files for which source code fingerprint scanning is performed.
- Include System Identified Files is Yes/No field that allows the scanner to skip source code files that have already been associated with inventory items.
- By default this option is unchecked and files associated with inventory items are not scanned for source matches.
- Include Files with Exact Matches is a Yes/No field that allows the scanner to skip source code files that are an exact match to files from the open source community.
- Be default, this option is unchecked, and files with exact matches are not scanned for source matches.
- Minimum Source Code Matches is a field that takes an integer input. This value is then compared to the number of snippet matches in the scanned source code file to determine whether the file is reported as having source matches.
- The default value is 3 matches, but several users set it to as high as 10 to speed up scan times while generally not causing false-negatives in the scan results.
- The appropriate number depends on the level of risk the project is willing to absorb with respect to files being reported as not having source matches even though a very small fragment of the file is a match to files from the open source community.
Search Terms
Search terms are great leading indicators of third-party content. Flexera provides several lists of search terms for various levels of analysis. The standard scan profile has a basic list of search terms, and the comprehensive scan profile extends that with additional terms.
Scan Exclusions
The list of scan exclusion can be used to inform the scanner about which codebase elements to skip during the scan. Refer to the Creating Exclusion Patterns for Scan Profiles chapter in the Installation and Configuration Guide for a detailed explanation of how to properly enter file patterns into the exclusions field.
{kind=link}